折腾记录
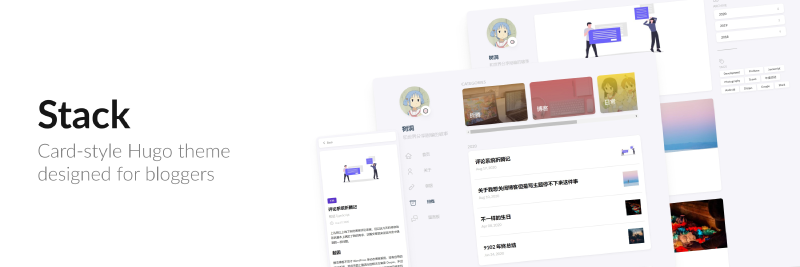
新博客,新起点:Hugo + Stack
博客从 Hexo 迁移到 Hugo 和 Stack 了
折腾记录
使用 AMT + PXE + Alpine 抢救一台远程 Proxmox VE 服务器
折腾记录
搞台 NAS (4):Openmediavault 通过 Docker 部署 qBittorrent
折腾记录
搞台 NAS (3):Openmediavault 部署 ZFS 文件系统
折腾记录
搞台 NAS (2):Openmediavault 的安装与配置
1
2
…
4